
Human Action Recognition in Time Series data using Deep Learning
Agenda
- Problem Statement: Use smartphone data to classify six human actions (walking, walking upstairs, walking downstairs, sitting, standing, laying).
- Data: Human Activity Recognition smartphone dataset: UCI HAR Dataset
- Methods:
- LSTM
- 1D CNN
- Results & Insights:
- 1D CNNs are faster to train and test. They will serve better in production.
Problem Statement
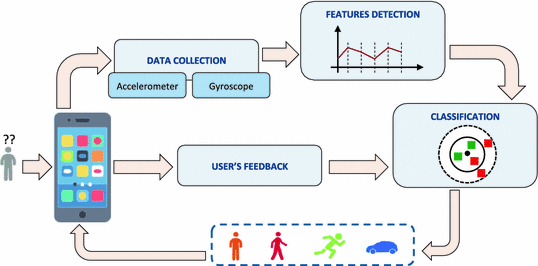
Human Action Recogntion aims to determine human activities given monitoring data from systems such as body sensors or videos. The process usually involves noise filtering the data and extracting pre-defined time series features. The problem with this approach is it requires domain expertise.
An alternative approach would be to use neural network architectures that can serve as feature extractors, thus eliminating the need for feature engineering. In this tutorial, you will learn LSTMs and how they stack up against 1-D CNNs.
Human Action Recognition has multiple applications from research into fall risk patients to surveillance systems. The main goal of this post is to classify six human actions (walking, walking upstairs, walking downstairs, sitting, standing, laying) based on time series data provided by a smartphone.
Data
We will be wrangling with the Human Activity Recognition Using Smartphones Data Set freely available in the UCI Machine Learning Repository.
The experiment was carried out by 30 participants. Each person performed six activities (WALKING, WALKING_UPSTAIRS, WALKING_DOWNSTAIRS, SITTING, STANDING, LAYING) wearing a smartphone (Samsung Galaxy S II) on the waist. Using its embedded accelerometer and gyroscope, the authors captured 3-axial linear acceleration and 3-axial angular velocity at a constant rate of 50Hz (50 samples/sec).
The sensor signals were pre-processed by applying noise filters and then sampled in fixed-width sliding windows of 2.56 sec and 50% overlap (128 readings/window). From each window, a vector of features was obtained (jerk, magnitude, etc.). However, we won’t rely on this 561-feature vector that requires domain expertise to create. Instead, we’ll let our neural network calculate the necessary features from the 6 original inertial signals:
- 3-axial signals for total acceleration (x,y,z)
- 3-axial signals for angular velocity (x,y,z)
Every row in the final dataset contains a 128 element vector with 6 signals. Therefore, each row contains 128*6, or 768 elements. The dataset has been randomly partitioned into two sets, where 70% of the volunteers were selected for generating the training data and 30% the test data.
Methods: LSTM vs. 1D-CNN
LSTM
Long Short-Term Memory (LSTM) networks are a type of recurrent neural network that can learn patterns over sequences. The main advantage of LSTMs over traditional machine learning techniques is that they require no feature engineering.
The custom_lstm() function below defines a stack of two LSTMs to process the input smart phone data.
def custom_lstm(lstm_units):
input_smartphone = Input(shape=(X_train.shape[1],X_train.shape[2]), name='input_smartphone')
x = LSTM(lstm_units, return_sequences=True)(input_smartphone)
x = LSTM(lstm_units, return_sequences=False)(x)
output = Dense(nb_classes, activation='softmax', name='output')(x)
model = Model(inputs=input_smartphone,outputs=output)
return model
1D-CNN
We can also use Convolutional Neural Networks (CNNs) to process the temporal data. There have been recent successes with such architectures in the domain of Natural Language Processing.
The custom_1d_cnn() function below defines a typical 1-dimensional CNN architecture with Max Pooling, Global Average Pooling, and Dropout intertwined to reduce overfitting.
def custom_1d_cnn(conv_units):
input_smartphone = Input(shape=(X_train.shape[1], X_train.shape[2] ), name='input_smartphone')
x = Conv1D(conv_units, kernel_size=3, activation='relu')(input_smartphone)
x = Conv1D(conv_units, kernel_size=3, activation='relu')(x)
x = MaxPool1D(pool_size=2)(x)
x = Conv1D(conv_units, kernel_size=3, activation='relu')(x)
x = Conv1D(conv_units, kernel_size=3, activation='relu')(x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.5)(x)
output = Dense(nb_classes, activation='softmax', name='output')(x)
model = Model(inputs=input_smartphone,outputs=output)
return model
Results & Insights
From the table below we can see that the LSTM and CNN models are comparable in size. Both sit roughly around 1.5 MB. However, the LSTM model takes 4X longer to run! Moreover, it seems that the LSTM model is slightly overfitting the training data as shown by the drop in accuracy when moving from training to validating. Both models take a slight hit in terms of accuracy when trying to predict the test set, but a slight drop for unseen data is to be expected.
| Model | Size (MB) | Runtime (X_train, 10 reps) | Accuracy (X_train) | Accuracy (X_val) | Accuracy (X_test) |
|---|---|---|---|---|---|
| LSTM | 1.5 | 20.4s +/- 1s | 96% | 92% | 86% |
| CNN | 1.8 | 5.2s +/- .8s | 92% | 90% | 86% |
Summary
In conclusion, when trying to perform human activity recognition using smart phone data, it’s better to use one-dimensional Convolutional Neural Networks over LSTMs due to the longer runtime for LSTMs.
Full code: Github